Management interface evolution
Since the early dawn of networking, devices have been configured through VTYs. The transport has evolved from telnet to ssh but the underlying rule still maintained that network is configured manually, device-by-device by a human administrator. It’s obvious that this approach does not scale and is prone to human error, however it still remains the most prevalent method of network device configuration.
The first attempt to tackle these issues has been made in 1988 with the introduction of SNMP. The basic idea was to monitor and manage network devices using a strictly-defined data structures called MIBs. Unfortunately, due to several architectural issues and poor vendor implementation, SNMP has ended up being used mainly for basic monitoring tasks.
The idea of programmatic management of network devices later resulted in the creation of NETCONF protocol. Despite being almost 10 years old, this protocol is still not widely used due to limited vendor support, however things may improve as the YANG-based network configuration gains greater adoption.
Finally, with the advent of SDN, REST has become a new de-facto standard for network provisioning. It is supported by most of the latest products of all the major vendors. Let’s take a closer look at what REST is and how it works.
REpresentational State Transfer overview
Technically speaking, REST is not a protocol but a software architectural pattern. To put it in simple words, it describes a way to exchange information rather than the structure of that information. Think of it as another transport (like telnet or ssh for VTY) for payloads of any format. Most commonly payload will get encoded as JSON, however the structure of JSON is not defined and is different for each application. This rather weak definition opens up huge opportunities for potential use cases:
The most basic use case is a Web application with client retrieving and updating information on a server. A good example in networking world would be the native interfaces of Cisco ACI or VMWare NSX. Each time you create an object (a network or a tenant) in a Web GUI, your client sends a request to server’s REST interface.
The more advanced use case is for communication between distributed software components over a network environment. This is how all management and control plane communications are designed inside OpenStack. For example, every time a new VM is created, Nova sends a request to Neutron’s REST API interface to allocate an IP address and a port for that VM.
REST under the hood
REST is an API that allows clients to perform read/write operations on data stored on the server. REST uses HTTP to perform a set of actions commonly known as CRUD:
- Create
- Read
- Update
- Delete
Assuming we want to manipulate a ‘device’ object on a server we can send an HTTP GET request to /api/devices and get a response with a payload containing a full list of known devices.
If we want to add a new device, we need to construct a payload with device attributes (e.g. IP address, Hostname) and send it attached to an HTTP POST request.
To update a device we need to send the full updated payload with HTTP PUT method.
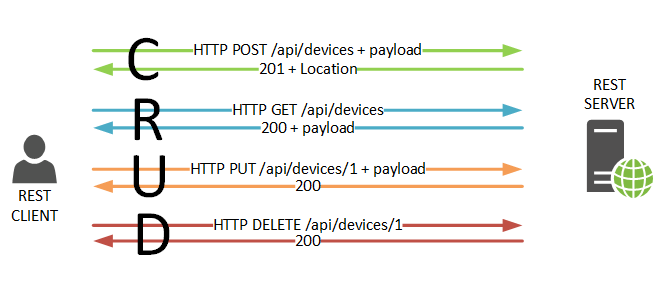
Note that both Update and Delete API calls refer to a specific number in url /api/devices/{ID}. That is a UUID that server assigns to every new object and is returned in Location header of 201 Created message sent in response to Create request.
REST API Constraints
For API to be considered RESTful it needs comply with a number of formal constraints. One of the most important constraint of all is the stateless nature of the interface. That means that no cookie or session information should be stored on the server, and every request is treated independently from every other request. The implication here is that all state needs to be maintained on the client and information needs to be cacheable in order to improve interface responsiveness.
It’s worth noting that an API can still be considered RESTful even if a server does store a session cookie, however all requests must still be treated independently. The last point means there’s no configuration modes like we’ve seen in traditional CLIs where all commands issued in “interface configuration mode” will be applied to that specific interface. With RESTful API each request from a client must reference a full path to an object including its UUID within the system.
Using REST
cURL
cURL is a light-weight Linux command-line tool for transferring data. It’s very simple to get started and very frequently used to make HTTP requests. For example, this is how you would issue a Read request to get a list of devices configured on an imaginary SDN controller:
$ curl -X GET http://sdn-controller.org:8181/api/devices
Obviously this tool is very good for fast prototyping and troubleshooting but becomes too cumbersome for anything involving more than a few commands.
Browser plugins
There’s plenty of GUI-based clients that can be added-on to most popular browsers. Postman and RESTClient are amongst the most popular ones. In addition to basic functionality, these plugins allow you to store and issue sequence of requests which can be very handy for live demonstrations. Unfortunately that’s where most of the people stop learning about REST API and assume this is the intended way to interact with a server.
SDK
Software Development Kit is a collection of tools and libraries that allow users to build a full-blown applications with complex internal logic. Instead of caring about the exact syntax of API calls, SDK libraries provide a simple programming interface. For example, this is how you would run the same command we did earlier with cURL:
controller = sdk.Controller('sdn-controller.org', 8181)
response = controller.get_devices()
We first create an instance of a controller with specific hostname and port number and then issue a .get_devices() call on it to obtain the list of all known devices. SDK library will do all the dirty work constructing HTTP request in the background and return the parsed information from HTTP response. We can then use that information to perform some complex logic, like start only Router devices (but not switches and firewalls):
routers_started = [device.start() for device in response.get_payload() if device.type == 'Router']
As you can see, we can use all capabilities of a programming language to write a succinct and powerful code, something that would be extremely difficult to do with cURL or Postman. That’s why the focus of this series of posts will be on the SDK, how to build one from scratch and how to use it.
UNetLab REST SDK
In the upcoming posts I’ll show how to develop a REST SDK to control UnetLab. My final goal would be to be able to create and fully configure an arbitrary network topology. The whole series will be broken up into several posts going over:
- UnetLab SDK development environment setup. I’ll show how to setup PyCharm to work with UNL running in a hypervisor on a Windows machine.
- First steps with REST API for UNetLab. In this post I’ll show how to work with HTTP and perform basic operations like login/logoff and object creation in UNL.
- Advanced actions with UNetLab SDK. The final post will demonstrate how to push configuration to devices inside UNL. To wrap up I’ll write a sample app to spin up and provision a three-node topology without making a single GUI click.