MAC learning in a controller-less VXLAN overlay
VXLAN standard does not specify any control plane protocol to exchange MAC-IP bindings between VTEPs. Instead it relies on data plane flood-and-learn behaviour, just like a normal switch. To force this behaviour in an underlay, the standard stipulates that each VXLAN network should be mapped to its own multicast address and each VTEP participating in a network should join the corresponding multicast group. That multicast group would be used to flood the BUM traffic in an underlay to all subscribed VTEPs thereby populating dynamic MAC address tables.
Default OpenvSwitch implementation does not support VXLAN multicast flooding and uses unicast source replication instead. This decision comes with a number of tradeoffs:
- Duplicate packets consume additional bandwidth. Extra 100 bytes exchanged every 3 minutes in a 100-nodes environment generate around 500 kbit/s of traffic on average. This can be considered negligible inside modern high-speed DC fabrics.
- Hardware VTEP gateways rely on multicast for MAC learning and VTEP discovery. As we’ll see later in the series, these gateways can now be controlled by Neutron just like a normal OVS inside a compute host.
- Duplicate packets are processed by hosts that do not need them, e.g. ARP request is processed by tunnel and integration bridges of all hosts that have VMs in the same broadcast domain. This presents some serious scaling limitation and is addressed by the L2 population feature described in this post.
Despite all the tradeoffs, OVS with unicast source replication has become a de-facto standard in most recent OpenStack implementations. The biggest advantage of such approach is the lack of requirement for multicast in the underlay network.
VXLAN MAC learning with an SDN controller
Neutron server is aware of all active MAC and IP addresses within the environment. This information can be used to prepopulate forwarding entries on all tunnel bridges. This is accomplished by a L2 population driver. However that in itself isn’t enough. Whenever a VM doesn’t know the destination MAC address, it will send a broadcast ARP request which needs to be intercepted and responded by a local host to stop it from being flooded in the network. The latter is accomplished by a feature called ARP responder which simulates the functionality commonly known as ARP proxy inside the tunnel bridge.
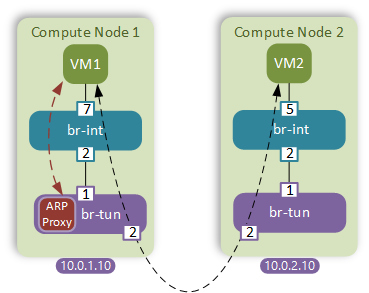
Configuration
Configuration of these two features is fairly straight-forward. First, we need to add L2 population to the list of supported mechanism drivers on our control node and restart the neutron server.
$ sed -ri 's/(mechanism_drivers.*)/\1,l2population/' /etc/neutron/plugin.ini
$ service neutron-server restart
Next we need to enable L2 population and ARP responder features on all 3 compute nodes.
$ sed -ri 's/.*(arp_responder).*/\1 = true/' /etc/neutron/plugins/ml2/openvswitch_agent.ini
$ sed -ri 's/.*(l2_population).*/\1 = true/' /etc/neutron/plugins/ml2/openvswitch_agent.ini
$ service neutron-openvswitch-agent restart
Since L2 population is triggered by the port_up messages, we might need to restart both our VMs for the change to take effect.
BUM frame from VM-1 for MAC address of VM-2 (Revisited)
Now let’s once again examine what happens when VM-1 issues an ARP request for VM-2’s MAC address (1a:bf).
First, the frame hits the flood-and-learn rule of the integration bridge and gets flooded down to the tunnel bridge as desribed in the previous post. Once in the br-tun, the frames gets matched by the incoming port and resubmitted to table 2. In addition to a default unicast/multicast bit match, table 2 now also matches all ARP requests and resubmitts them to the new table 21. Note how the ARP entry has a higher priority to always match before the default catch-all multicast rule.
$ ovs-ofctl dump-flows br-tun
table=0, priority=1,in_port=1 actions=resubmit(,2)
table=2, priority=1,arp,dl_dst=ff:ff:ff:ff:ff:ff actions=resubmit(,21)
table=2, priority=0,dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20)
table=2, priority=0,dl_dst=01:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,22)
Inside table 21 are the entries created by the ARP responder feature. The following is an example entry that matches all ARP requests where target IP address field equals the IP of VM-2(10.0.0.9).
$ ovs-ofctl dump-flows br-tun
table=21, priority=1,arp,dl_vlan=1,arp_tpa=10.0.0.9
actions=move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],
mod_dl_src:fa:16:3e:ab:1a:bf,
load:0x2->NXM_OF_ARP_OP[],
move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],
move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],
load:0xfa163eab1abf->NXM_NX_ARP_SHA[],
load:0xa000009->NXM_OF_ARP_SPA[],
IN_PORT
The resulting action builds an ARP response by modifying the fields and headers on the original ARP request message, specifically OVS:
- Copies the source MAC address (VM-1) to the destination MAC address header
- Spoofs the source MAC address to make it look like it comes from VM-2
- Modifies the operation code of ARP message to 0x2, meaning reply
- Overwrites the target IP and MAC address fields inside the ARP packet with VM-1’s values
- Overwrites the source hardware address with VM-2’s MAC
- Overwrites the source IP address with the address of VM-2(0xa000009)
- Sends the packet out the port from which it was received
Unicast frame from VM-1 to VM-2 (Revisited)
Now that VM-1 has learned the MAC address of VM-2 it can start sending the unicast frames. The first few steps will again be the same. The frame hits the tunnel bridge, gets classified as a unicast and resubmitted to table 20. Table 20 will still have an entry generated by a learn action triggered by a packet coming from VM-2, however now it also has and identical entry with a higher priority(priority=2), which was preconfigured by a L2 population feature.
table=0, priority=1,in_port=1 actions=resubmit(,2)
table=2, priority=0,dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20)
table=20, priority=2,dl_vlan=1,dl_dst=fa:16:3e:ab:1a:bf actions=strip_vlan,set_tunnel:0x54,output:2
table=20, priority=1,vlan_tci=0x0001/0x0fff,dl_dst=fa:16:3e:ab:1a:bf actions=load:0->NXM_OF_VLAN_TCI[],load:0x54->NXM_NX_TUN_ID[],output:2
Other BUM traffic
The two features described in this post only affect the ARP traffic to VMs known to the Neutron server. All the other BUM traffic will still be flooded as described in the previous post.
Results
As the result of enabling L2 population and ARP responder features we were able to reduce the amount of BUM traffic in the overlay network and reduce the eliminate processing on compute hosts incurred by ARP request flooding.
However one downside of this approach is the increased number of flow entries in tunnel bridges of compute hosts. Specifically, for each known VM there now will be two entries in the tunnel bridge with different priorities. This may have negative impact on performance and is something to keep in mind when designing OpenStack solutions for scale.
Coming Up
In the next post I’ll show how to overcome the requirement of a direct L2 adjacency between the network node and external subnet. Specifically, I’ll use Arista switch to extend a L2 provider network over a L3 leaf-spine Cisco fabric.