Provider vs Tenant networks
Before we start, let’s recap the difference between the two major Neutron network types:
- Tenant networks are:
- provisioned by tenants
- used for inter-VM (east-west) communication
- use Neutron virtual router as their default gateway
- Provider networks are:
- provisioned by OpenStack administrator(for use by tenants)
- match existing physical networks
- can be either flat (untagged VLAN) or VLAN-based (multiple VLANs)
- need to be L2 adjacent to network and/or compute nodes
These two network types are not mutually exclusive. In our case the admin tenant network is implemented as a VXLAN-based overlay whose only requirement is to have a layer-3 reachability in the underlay. However tenant network could also have been implemented using a VLAN-based provider network in which case a set of dot1Q tags pre-provisioned in the underlay would have been used for tenant network segregation.
External provider network
External network is used by VMs to communicate with the outside world (north-south). Since default gateway is located outside of OpenStack environment this, by definition, is a provider network. Normally, tenant networks will use the non-routable address space and will rely on a Neutron virtual router to perform some form of NAT translation. As we’ve seen in the earlier post, Neutron virtual router is directly connected to the external bridge which allows it to “borrow” ip address from the external provider network to use for two types of NAT operations:
- SNAT - a source-based port address translation performed by the Neutron virtual router
- DNAT - a static NAT created for every floating ip address configured for a VM
In default deployments all NATing functionality is performed by a network node, so external provider network only needs to be L2 adjacent with a limited number of physical hosts. In deployments where DVR is used, the virtual router and NAT functionality gets distributed among all compute hosts which means that they, too, now need to be layer-2 adjacent to the external network.
Solutions overview
The direct adjacency requirement presents a big problem for deployments where layer-3 routed underlay is used for the tenant networks. There is a limited number of ways to satisfy this requirements, for example:
- Span a L2 segment across the whole DC fabric. This means that the fabric needs to be converted to layer-2, reintroducing spanning-tree and all the unique vendor solutions to overcome STP limitations(e.g. TRILL, Fabripath, SPB).
- Build a dedicated physical network. This may not always be feasible, especially considering that it needs to be delivered to all compute hosts.
- Extend the provider network over an existing L3 fabric with VXLAN overlay. This can easily be implemented with just a few commands, however it requires a border leaf switch capable of performing VXLAN-VLAN translation.
Detailed design
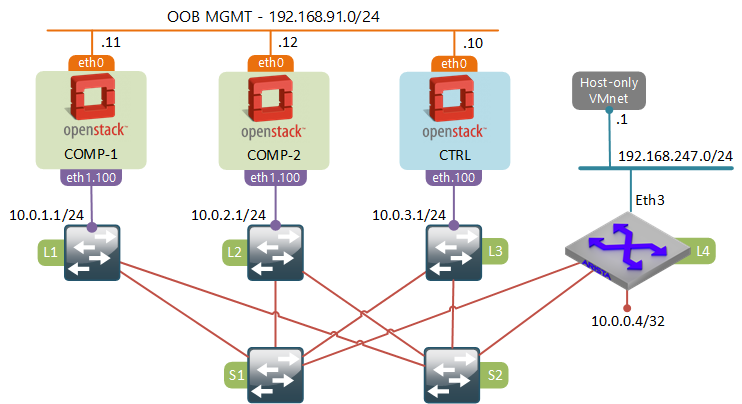
As I’ve said in my earlier post, I’ve built the leaf-spine fabric out of Cisco IOU virtual switches, however the plan was to start introducing other vendors later in the series. So this time for the border leaf role I’ve chosen Arista vEOS switch, however, technically, it could have been any other vendor capable of doing VXLAN-VLAN bridging (e.g. any hardware switch with Trident 2 or similar ASIC).
Arista vEOS configuration
Configuration of Arista switches is very similar to Cisco IOS. In fact, I was able to complete all interface and OSPF routing configuration only with the help of CLI context help. The only bit that was new to me and that I had to lookup in the official guide was the VXLAN configuration. These similarities makes the transition from Cisco to Arista very easy and I can understand (but not approve!) why Cisco would file a lawsuit against Arista for copying its “industry-standard CLI”.
interface Ethernet1
description SPINE-1:Eth0/3
no switchport
ip address 169.254.41.4/24
ip ospf network point-to-point
!
interface Ethernet2
description SPINE-2:Eth0/3
no switchport
ip address 169.254.42.4/24
ip ospf network point-to-point
!
interface Ethernet3
description VM-HOST-ONLY:PNET1
switchport access vlan 100
spanning-tree portfast
!
interface Loopback0
ip address 10.0.0.4/32
!
interface Vxlan1
vxlan source-interface Loopback0
vxlan udp-port 4789
vxlan vlan 100 vni 1000
vxlan vlan 100 flood vtep 10.0.3.10
!
router ospf 1
router-id 10.0.0.4
passive-interface default
no passive-interface Ethernet1
no passive-interface Ethernet2
network 0.0.0.0/0 area 0.0.0.0
!
Interface VXLAN1 sets up VXLAN-VLAN bridging between VNI 1000 and VLAN 100. VLAN 100 is used to connect to VMware Workstation’s host-only interface, the one that was previously connected directly to the L3 leaf switch. VXLAN interface does the multicast source replication by flooding unknown packets over the layer 3 fabric to the network node (10.0.3.10).
OpenStack network node configuration
Since we don’t yet have the distributed routing feature enabled, the only OpenStack component that requires any changes is the network node. First, let’s remove the physical interface from the external bridge, since it will no longer be used to connect to the external provider network.
$ ovs-vsctl del-port br-ex eth1.300
Next let’s add the VXLAN interface towards the Loopback IP address of the Arista border leaf switch. The key option sets the VNI which must be equal to the VNI defined on the border leaf.
$ ovs-vsctl add-port br-ex vxlan1 \
-- set interface vxlan1 \
type=vxlan \
options:remote_ip=10.0.0.4 \
options:key=1000
Without any physical interfaces attached to the external bridge, the OVS will use the Linux network stack to find the outgoing interface. When a packet hits the vxlan1 interface of the br-ex, it will get encapsulated in a VXLAN header and passed on to the OS network stack where it will follow the pre-configured static route forwarding all 10/8 traffic towards the leaf-spine fabric. Check out this article if you want to learn more about different types of interfaces and traffic forwarding behaviours in OpenvSwitch.
Cleanup
In order to make changes persistent and prevent the static interface configuration from interfering with OVS, remove all OVS-related configuration and shutdown interface eth1.300.
ONBOOT=no
VLAN=yes
Change in the packet flow
None of the packet flows have changed as the result of this modification. All VMs will still use NAT to break out of the private environment, the NAT’d packets will reach the external bridge br-ex as described in my earlier post. However this time br-ex will forward the packets out the vxlan1 port which will deliver them to the Arista switch over the same L3 fabric used for east-west communication.
If we did a capture on the fabric-facing interface eth1 of the control node while running a ping from one of the VMs to the external IP address, we would see a VXLAN-encapsulated packet destined for the Loopback IP of L4 leaf switch.

Coming Up
In the next post we’ll examine the L2 gateway feature that allows tenant networks to communicate with physical servers through yet another VXLAN-VLAN hardware gateway.