In the past few years, network automation has made its way from a new and fancy way of configuring devices to a well-recognized industry practice. What started as a series of “hello world” examples has evolved into an entire discipline with books, professional certifications and dedicated career paths. It’s safe to say that today, most large-scale networks (>100 devices) are at least deployed (day 0) and sometimes managed (day 1+) using an automated workflow. However, at the heart of these workflows are the same exact principles and tools that were used in the early days. Of course, these tools have evolved and matured but they still have the same scope and limitations. Very often, these limitations are only becoming obvious once we hit a certain scale or complexity, which makes it even more difficult to replace them. The easiest option is to accept and work around them, forcing the square peg down the round hole. In this post, I’d like to propose an alternative approach to what I’d consider “traditional” network automation practices by shifting the focus from “driving the CLI” to the management of data. I believe that this adjustment will enable us to build automation workflows that are much more robust and scalable and there are emerging tools and practices that were designed to address exactly that.
Evolution of Network Configuration Management
In order to understand why data management is important, we need to have a closer look at what constitutes a typical network automation workflow. The most basic process starts by combining a device data model, represented by a free-form data structure (e.g. YAML), with a text template (e.g. Jinja) to produce the desired device configuration. This configuration is then passed to a function that implements the underlying transport protocol (e.g. netmiko), which applies the desired changes. Some of these steps can be abstracted away by automation frameworks (e.g. Ansible) but largely the process still looks the same under the hood. This is what you can see on the left-hand side of the following diagram:
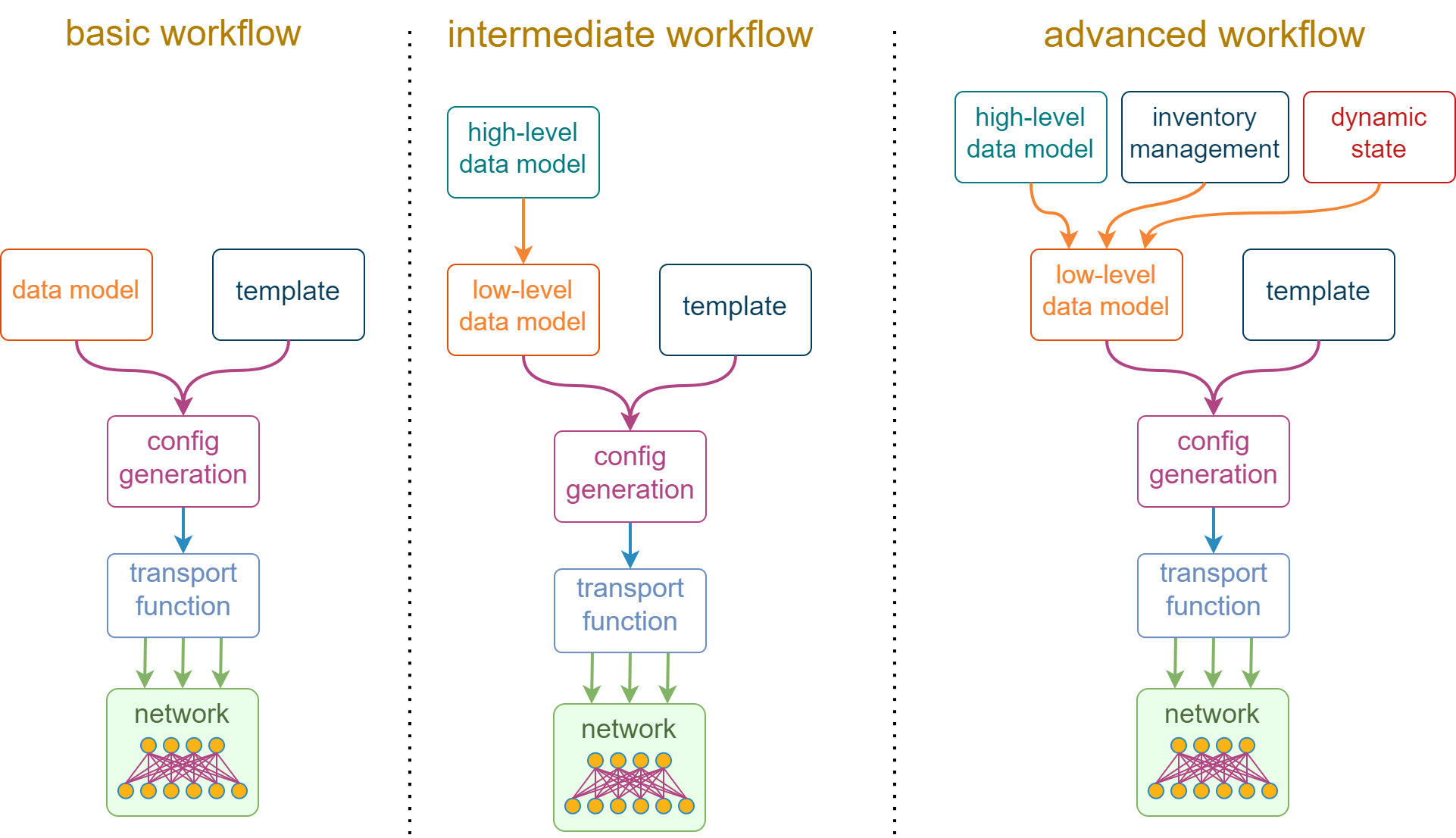
While the basic workflow may work well for the initial network configuration, it is rarely suitable for ongoing operations due to its inherent verbosity. The natural reaction to that is to create another layer of abstraction that hides common design conventions, configuration defaults and computable attributes behind a terse high-level data model, as depicted by the “intermediate workflow” in the above diagram. This high-level data model simplifies the end-user experience of interacting with the automation workflow, but it comes at the expense of additional complexity hidden in the high-to-low-level translation logic.
Finally, some physical networks have decided to replicate the self-service cloud experience by allowing some parts of their state to be managed dynamically. One simple example is to allow a compute team to manage the VLAN assignment on the downlink network ports. This meant that a single, flat-text data structure is no longer enough to store the high-level configuration intent, and we split it across multiple (preferably) non-overlapping sources of truth, visualized by the “advanced workflow” in the above diagram.
If you look at the above diagram, you might notice one theme that emerges and evolves together with the complexity of automation workflows. It is the ever-increasing focus on data. Thanks to the growing number of templates, we started caring less about individual vendor configuration dialects and more about how to source, structure and combine input configuration values. I would argue that these input values have become the new API, since the old APIs (“industry-standard” CLI) were not built for automation and eventually got abstracted away by libraries like scrapli or netmiko and a ton of (mostly) Jinja templates.
The same argument can be applied to the YANG-based APIs, which were designed for machine-to-machine communication and are slowly but steadily getting more traction. Those APIs are often abstracted away by software platforms, such as OpenDaylight or Tail-f NSO, or libraries like ygot, and operational tasks are, once again, reduced to the management of input data.
Automation Tools
I want to frame the discussion of automation tools in the context of the configuration complexity clock. The main premise of this theory is that the process of finding the right level of abstraction for configuration values is cyclical. Here’s my free interpretation of the original story, translated into the network automation reality:
- 00:00: We need to configure a network but don’t have time for proper planning, so we have all configurable values hard-coded in flat-text configuration files and simply push them to network devices.
- 03:00: We realise that some parts of the network need to change, so we extract some of the hard-coded values, simplify them and make them configurable.
- 06:00: The size of the configurable values continues to grow and we start building guardrails to prevent typical configuration mistakes and guarantee value uniqueness across the environment. We create a schema to validate input data and may even expose it via a GUI.
- 09:00: At some point the guard rails, schemas and policy engines start being a hurdle and we decide to consolidate all of them in a single framework, driven by its own DSL. Quickly realising that the framework can not meet all our requirements, we start extending it with custom code.
- 12:00: Now we have all our policies embedded in custom framework extensions and values hard-coded in the DSL, the network management process looks not much different from where we started.
Strictly speaking, this is more of a fable than a theory. It shows what a constant strive for improvement can do to an application’s user interface. If you read the original article, the author says that very few organisations go all the way around the clock, which means the majority settle somewhere in between. If we look at the current state of network automation, we can see a confirmation of that – majority of the network operators settle on one of the following two options:
- Everything is done with a DSL (Ansible + Jinja)
- Everything is done with a general-purpose programming language (Python)
Similar to the choice of their preferred hardware vendor, the choice between the above two options can be almost religious to some people. There are engineers who wouldn’t want to come close to Ansible and there are those who shove all the logic into Ansible DSL, ignoring the exponentially-increasing complexity. The most important point is that both groups seem to have settled on their choice and accepted the caveats and limitations resulting from their decisions. So far, I have not seen any attempts to upset this status quo by exploring and explaining alternative options.
What if there was another option that would allow us to write a true statically-typed code instead of using type hints, avoid variable override hell, with built-in low-cost concurrency and task orchestration? What if we could use a tool that was purposefully built to transform and generate configuration data instead of engaging in Jinja programming with Ansible (that was never designed for this) or trying to write error-proof and readable Python?
The author of the configuration complexity clock article cautions us against making rash decisions (especially from rolling your own DSL) and also suggests that at a low-enough scale simpler solutions may be the best option. I would agree with him. If you think that you get enough out of your current automation solution – you don’t feel like you’re swimming against the tide all the time and you’re confident that when you move on, the next person will be able to pick up and continue your work without re-write everything from scratch – then you don’t need to change. However, I’d like to show you that you can do better. You can create a solution that is faster, more robust to failures and easier to understand and extend. Like with anything new, there’s a price you have to pay, by learning and changing your automation workflows, but the ultimate benefit may very well be worth it.
Introducing CUE
CUE or cuelang was built to manage configuration data which, as we’ve seen above, is one of the most critical parts of advanced network automation workflows. CUE tries to strike a balance between the simplicity of a DSL and the efficiency of a general-purpose programming language. Visually, it looks very similar to JSON (it is a superset of JSON) with a relaxed grammar, e.g. you can leave comments and omit string quotes for field names. This is an example of a CUE syntax that defines a set of BGP configuration values:
bgp: {
asn: 65123
router_id: "192.0.2.1"
neighbors: {
swp51: {
unnumbered: true
remote_as: "external"
}
swp52: {
unnumbered: true
remote_as: "external"
}
}
}
The main idea is that you write all your configuration values, constraints and code generation rules in CUE code. It becomes your new source of truth and can later output values in YAML or JSON format, which you can either pass to a text template (e.g. Jinja) to generate a semi-structured configuration or send as-is to a remote device (in case it supports structured input).
One of the two strongest qualities of CUE for network automation workflows (in my opinion) is static data typing. While we can work with the free-form data defined above, we can easily create a simple schema that would ensure that both the shape of the bgp struct and the type of all its values are exactly what we’d expect. Here’s the most straightforward way of doing this – we define another data structure with the same name, CUE will unify them and validate the values above are correct:
bgp: {
asn: int
router_id: net.IPv4 & string
neighbors: [=~"^swp"]: {
unnumbered: bool | *true
remote_as: int | "external" | "internal"
}
}
In the above example, we mix static typing (asn value must be an integer) with constraints (router_id is a string that is also a valid IPv4 address), defaults (default value for unnumbered is true) and regex matching (only apply the constraints and defaults to neighbors starting with swp). Now we can safely add or remove additional types and constraints as our data evolves, relying on CUE to produce the correct configuration values.
Another big selling point of CUE is its powerful data templating and generation capabilities. CUE natively supports value interpolation, conditional fields and for loops which allow us to generate larger data sets from smaller, more concise inputs. In addition, you can import helper packages from CUE’s standard library to perform common data operations. The following contrived example demonstrates the use of field comprehension (the for loop), local variables (the let keyword), conditionals and two helper packages from the standard library:
import (
"strings"
"strconv"
)
uplinks: ["swp53", "swp54"]
bgp: neighbors: {
for uplink in uplinks {
let parts = strings.SplitAfter(uplink, "swp")
if len(parts) > 1 {
let intfNum = strconv.ParseInt(parts[1], 10, 32)
if intfNum >= 50 {
"\(uplink)": {
remote_as: "external"
}
}
}
}
}
You can find the above code examples in the CUE playground (link) and experiment by changing the values and observing the result, for example:
- Change the
asnfield to a string instead of an integer - Try adding a couple of new values to the
uplinklist, e.g.swp50,swp49 - Change the
router_idfield to contain an invalid IPv4 address - In the drop-down menu at the top of the page, change the output to JSON or YAML
With the examples above, we’re just scratching the surface of what CUE is capable of. Things I haven’t covered here include module packaging, integration with OpenAPI, YAML, JSON and Go, and the built-in support for external network calls. The goal of the current article is mainly to whet your appetite but I’ll try to cover these and other interesting features in the following blog posts. Here’s what you can expect to find about in the upcoming material:
- Augment your existing Ansible-based automation workflow with CUE
- How to use CUE for YANG-based APIs
- Orchestrate API interactions with remote devices
- Reducing configuration boilerplate
- Performance comparison of CUE vs Ansible