Last week I posted a tweet about a Kubernetes networking puzzle. In this post, we’ll go over the details of this puzzle and uncover the true cause and motive of the misbehaving ingress.
Puzzle recap
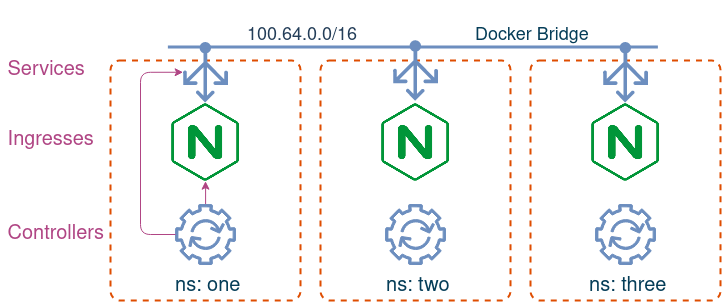
Imagine you have a Kubernetes cluster with three namespaces, each with its own namespace-scoped ingress controller. You’ve created an ingress in each namespace that exposes a simple web application. You’ve checked one of them, made sure it works and moved on to other things. However some time later, you get reports that the web app is unavailable. You go to check it again and indeed, the page is not responding, although nothing has changed in the cluster. In fact, you realise that the problem is intermittent - one minute you can access the page, and on the next refresh it’s gone. To make things worse, you realise that similar issues affect the other two ingresses.
If you feel like you’re capable of solving it on your own, feel free to follow the steps in the walkthrough, otherwise, continue on reading. In either case, make sure you’ve setup a local test environment so that it’s easier to follow along:
Clone the ingress-puzzle repo:
git clone https://github.com/networkop/ingress-puzzle && cd ingress-puzzleBuild a local test cluster:
make clusterCreate three namespaces:
make namespacesCreate an in-cluster load-balancer (MetalLB) that will allocate IPs from a
100.64.0.0/16range:make load-balancerIn each namespace, install a namespace-scoped ingress controller:
make controllersCreate three test deployments and expose them via ingresses:
make ingresses
Ingress controller expected behaviour
In order to solve this puzzle we need to understand how ingress controllers perform their duties, so let’s see how a typical ingress controller does that:
- An ingress controller consists of two components - control plane and data plane, which can be run separately or be a part of the same pod/deployment.
- Control plane is a k8s controller that uses its pod’s service account to talk to the API server and establishes “watches” on
Ingress-type resources. - Data plane is a reverse proxy (e.g. nginx, envoy) that receives traffic from end users and forwards it upstream to one of the backend k8s services.
- In order to steer the traffic to the data plane, an external load-balancer service is required, whose address (IP or hostname) is reflected in ingress’s status field.
- As
Ingressresources get created/deleted, controller updates configuration of its data plane to match the desired state described in those resources.
This sounds simple enough, but as always, the devil is in the details, so let’s start by focusing on one of the namespaces and observe the behaviour of its ingress.
Exhibit #1 - namespace one
Let’s looks at the ingress in namespace one. It seems like a healthy-looking output, the address is set to the 100.64.0.0 which is part of the MetalLB range.
$ kubens one
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test <none> * 100.64.0.0 80 141m
If you want to test connectivity to the backend deployment, you can add the MetalLB public IP range to the docker bridge like this:
ip=$(kubectl get nodes -o jsonpath='{.items[0].status.addresses[0].address}')
device=$(ip -j route get $ip | jq '.[0].dev')
sudo ip addr add 100.64.0.100/16 dev $device
Now you should be able to hit the test nginx deployment:
curl -s 100.64.0.0 | grep Welcome
<title>Welcome to nginx!</title>
<h1>Welcome to nginx!</h1>
Nothing unusual so far, and nothing to indicate intermittent connectivity either. Let’s move on.
Exhibit #2 - namespaces two & three
This output looks a bit weird, the IP in the address field is definitely not a part of the MetalLB range:
$ kubens two
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test <none> * 172.18.0.2 80 155m
A similar situation can be observed in the other namespace:
$ kubens three
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test <none> * 172.18.0.2 80 155m
At this point, these outputs don’t make a lot of sense. How can two different ingresses, controlled by two distinct controllers have the same address? And why do they get allocated with a private IP, which is not managed by MetalLB? If we check services across all existing namespaces, there won’t be a single service with IPs from 172.16.0.0/12 range.
kubectl get svc -A | grep 172
Exhibit #4 - flapping addresses
Another one of the reported issues was the intermittent connectivity to some of the ingresses. If we keep watching the ingress in namespace one, we should see something interesting:
kubens one
kubectl get ingress --watch
NAME CLASS HOSTS ADDRESS PORTS AGE
test <none> * 100.64.0.0 80 141m
test <none> * 172.18.0.2 80 141m
test <none> * 100.64.0.0 80 142m
test <none> * 172.18.0.2 80 142m
test <none> * 100.64.0.0 80 143m
test <none> * 172.18.0.2 80 143m
test <none> * 100.64.0.0 80 144m
test <none> * 172.18.0.2 80 144m
It looks like the ingress address is flapping between our “good” MetalLB IP and the same exact IP that the other two ingresses have. Now let’s zoom out a bit and have a look at all three ingresses at the same time:
kubectl get ingress --watch -A
NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
one test <none> * 172.18.0.2 80 150m
three test <none> * 172.18.0.2 80 150m
two test <none> * 172.18.0.2 80 150m
one test <none> * 100.64.0.0 80 150m
three test <none> * 100.64.0.2 80 151m
three test <none> * 172.18.0.2 80 151m
one test <none> * 172.18.0.2 80 151m
one test <none> * 100.64.0.0 80 151m
three test <none> * 100.64.0.2 80 152m
one test <none> * 172.18.0.2 80 152m
three test <none> * 172.18.0.2 80 152m
one test <none> * 100.64.0.0 80 152m
This looks even more puzzling - it seems that all ingresses have addresses that flap continuously. This would definitely explain the intermittent connectivity, however the most important question now is “why”.
Exhibit #5 - controller logs
The most obvious suspect at this stage is the ingress controller, since it’s the one that updates the status of its managed ingress resources. Let stay in the same namespace and look at its logs:
kubectl logs deploy/ingress-ingress-nginx-controller -f
event.go:278] Event(v1.ObjectReference{Kind:"Ingress", Namespace:"one", Name:"test", UID:"7d1e4069-d285-4cf8-ba28-437d0a8fd04d", APIVersion:"networking.k8s.io/v1beta1", ResourceVersion:"55860", FieldPath:""}): type: 'Normal' reason: 'UPDATE' Ingress one/test
status.go:275] updating Ingress one/test status from [{172.18.0.2 }] to [{100.64.0.0 }]
event.go:278] Event(v1.ObjectReference{Kind:"Ingress", Namespace:"one", Name:"test", UID:"7d1e4069-d285-4cf8-ba28-437d0a8fd04d", APIVersion:"networking.k8s.io/v1beta1", ResourceVersion:"55870", FieldPath:""}): type: 'Normal' reason: 'UPDATE' Ingress one/test
This doesn’t make a lot of sense - the ingress controller clearly updates the status with the right IP, but why does it get overwritten? and by whom?
Exhibit #5 - cluster-wide logs
At this point, we can allow ourselves a little bit of cheating. Since it’s a test cluster and we’ve only got a few ingresses configured, we can tail logs from all ingress controllers and watch all ingresses at the same time. Don’t forget to install stern.
kubectl get ingress -A -w &
stern --all-namespaces -l app.kubernetes.io/name=ingress-nginx &
three ingress-ingress-nginx-controller-58b79c576b-94v8d controller status.go:275] updating Ingress three/test status from [{172.18.0.2 }] to [{100.64.0.2 }]
three test <none> * 100.64.0.2 80 174m
twothree ingress-ingress-nginx-controller-5db5984d7d-vljth ingress-ingress-nginx-controller-58b79c576b-94v8d controller event.go:278] Event(v1.ObjectReference{Kind:"Ingress", Namespace:"three", Name:"test", UID:"176f0f8e-d3d5-4476-9b51-2d02c7eb47e2", APIVersion:"networking.k8s.io/v1beta1", ResourceVersion:"57195", FieldPath:""}): type: 'Normal' reason: 'UPDATE' Ingress three/test
event.go:278] Event(v1.ObjectReference{Kind:"Ingress", Namespace:"three", Name:"test", UID:"176f0f8e-d3d5-4476-9b51-2d02c7eb47e2", APIVersion:"networking.k8s.io/v1beta1", ResourceVersion:"57195", FieldPath:""}): type: 'Normal' reason: 'UPDATE' Ingress three/test
two ingress-ingress-nginx-controller-5db5984d7d-vljth controller status.go:275] updating Ingress one/test status from [{100.64.0.0 }] to [{172.18.0.2 }]
two ingress-ingress-nginx-controller-5db5984d7d-vljth controller status.go:275] updating Ingress three/test status from [{100.64.0.2 }] to [{172.18.0.2 }]
three test <none> * 172.18.0.2 80 174m
Whodunit
So, it looks like the culprit is the ingress controller in namespace two and it tries to change status fields of all three ingresses. Now it’s safe to look at exactly how it was installed, and this is the helm values file:
controller:
publishService:
enabled: false
pathOverride: "two/svc"
scope:
enabled: false
admissionWebhooks:
enabled: false
It looks like the scope variable is set incorrectly so the ingress controller defaults to trying to manage ingresses across all namespaces. This should be an easy fix - just change the scope to true and upgrade the chart.
However, this still doesn’t explain the private IP address or its origin. Let’s try the following command:
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP
ingress-puzzle-control-plane Ready master 5h3m v1.18.2 172.18.0.2
So this is where it comes from - it’s the IP of the k8s node we’ve been running our tests on. But why would it get allocated to an ingress? To understand that we need to have a look at the nginx-ingress controller source code, specifically this function from status.go:
func (s *statusSync) runningAddresses() ([]string, error) {
if s.PublishStatusAddress != "" {
return []string{s.PublishStatusAddress}, nil
}
if s.PublishService != "" {
return statusAddressFromService(s.PublishService, s.Client)
}
// get information about all the pods running the ingress controller
pods, err := s.Client.CoreV1().Pods(s.pod.Namespace).List(context.TODO(), metav1.ListOptions{
LabelSelector: labels.SelectorFromSet(s.pod.Labels).String(),
})
if err != nil {
return nil, err
}
addrs := make([]string, 0)
for _, pod := range pods.Items {
// only Running pods are valid
if pod.Status.Phase != apiv1.PodRunning {
continue
}
name := k8s.GetNodeIPOrName(s.Client, pod.Spec.NodeName, s.UseNodeInternalIP)
if !sliceutils.StringInSlice(name, addrs) {
addrs = append(addrs, name)
}
}
return addrs, nil
}
This is how the nginx-ingress controller determines the address to report in the ingress status:
- Check if the address is statically set with the
--publish-status-addressflag. - Try to collect addresses from a published service (load-balancer).
- If both of the above have failed, get the list of pods and return the IPs of the nodes they are running on.
This last bit is why we had that private IP in the status field. If you look at the above values YAML again, you’ll see that the publishService value is overridden with a static service called svc. However, because this service doesn’t exist and was never created, the ingress controller will fail to collect the right IP and will fall through to step 3.
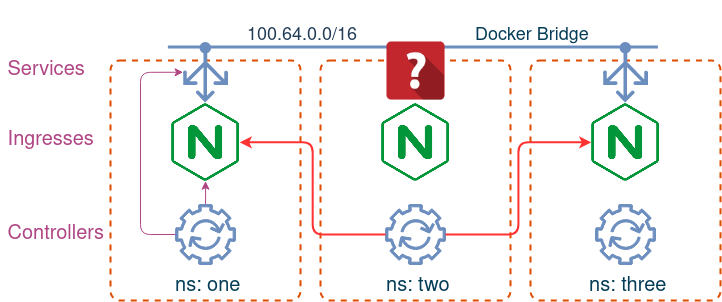
The logic described above is quite common and is also implemented by Kong ingress controller. The idea is that if your k8s nodes are running in a cluster with public IPs, this should still make the ingress accessible, even without a load-balancer.